ExisEcho: Fuzzy Logic Data Deduplication Software
The World's Most Flexible, Fastest, Highest Volume, and Most Sophisticated Data Deduplication System
Find similar but not identical records across any data source using advanced fuzzy logic data deduplication. Powered by intelligent algorithms that adapt to your data, ExisEcho delivers unmatched accuracy and performance for enterprise-grade duplicate detection and record matching.
Learn more about fuzzy logic data deduplication →
Need to clean up messy addresses? See our address matching software →
10+
Data Sources Supported
15+
Matching Options
99%
Match Accuracy
1M+
Records Per Minute
See ExisEcho in Action
Watch how easy it is to find duplicates in your data
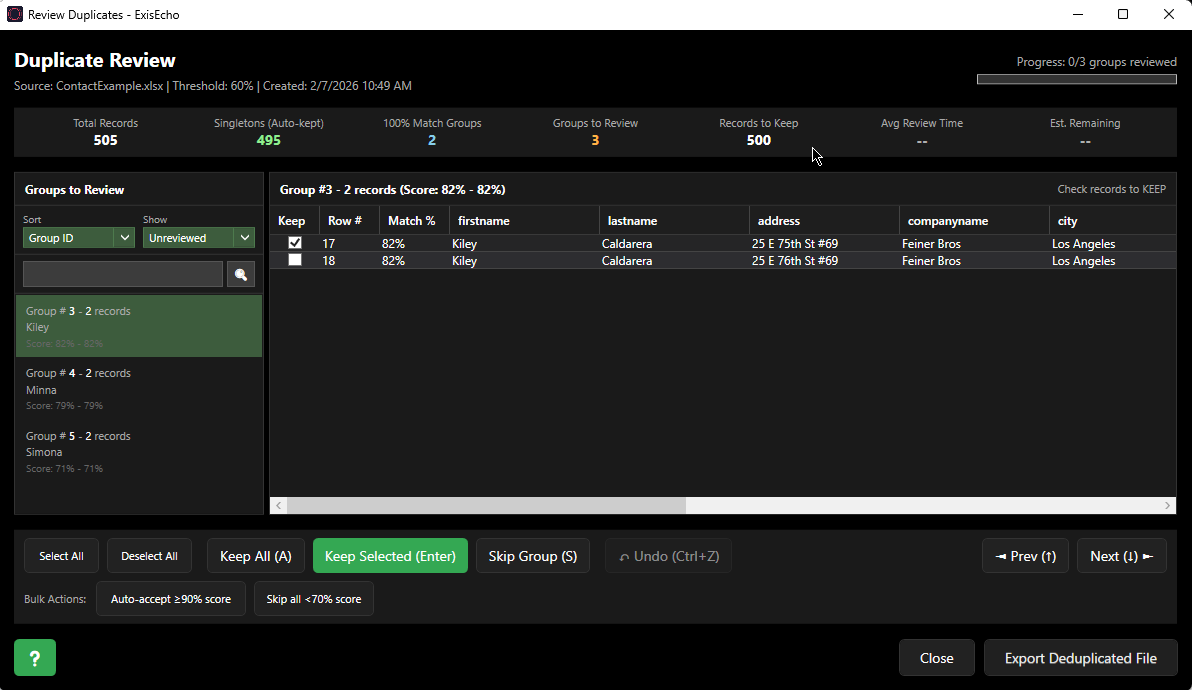
Review Duplicates & Export a Clean Unique List
The most powerful duplicate review workflow available—maintain full control while benefiting from intelligent automation
📊 Smart Categorization
Records are automatically sorted: unique singletons, 100% matches (auto-merged), and groups needing your review.
⚡ Quick Actions
Keep All, Keep Selected, or Skip Group with one click. Keyboard shortcuts let you fly through reviews.
💾 Auto-Save Progress
Close anytime and resume where you left off. Perfect for reviewing large datasets across multiple sessions.
📤 Export Clean Data
Generate a deduplicated Excel or CSV file containing only the records you chose to keep.
Powerful Data Deduplication Features
Everything you need for fuzzy logic data deduplication with precision and speed
Advanced Fuzzy Matching
Proprietary algorithms that find similar records even with typos, abbreviations, and variations. Goes beyond simple string matching to understand data semantically.
Phonetic Matching
Match names and words that sound alike but are spelled differently. Perfect for catching "Smith" vs "Smyth" or "John" vs "Jon" variations.
Weighted Scoring
Assign importance weights to different columns. Give more significance to critical fields like names while reducing weight on less important data.
Blazing Fast Performance
Optimized indexing technology processes millions of records in minutes, not hours. Built for enterprise-scale data volumes.
Highly Configurable
15+ matching options per column including synonym matching, title/article removal, case sensitivity, word order flexibility, and custom value filtering.
Synonym Support
Define your own synonym dictionaries. Match "Robert" with "Bob", "William" with "Bill", or industry-specific abbreviations with their full forms.
Address Matching Software
Intelligent fuzzy logic address matching handles abbreviations (St/Street, Ave/Avenue), city nicknames (NYC/New York), and formatting variations automatically.
Data Normalization
Automatically remove punctuation, articles, titles, numerics, or custom patterns before matching. Clean data leads to better matches.
Regex Filtering
Apply powerful regular expression filters to extract and match specific patterns within your data fields.
Similarity Scoring
Get precise percentage scores for each potential match. Set your own thresholds to control match sensitivity.
Interactive Duplicate Review
Review duplicate groups one by one, decide which records to keep, and export a clean deduplicated file. Progress auto-saves so you can resume anytime.
Export Unique List
After reviewing duplicates, export only the records you choose to keep. Generate a clean Excel or CSV file with no duplicates—ready for production use.
Connect to Any Data Source
ExisEcho works with the data sources you already use
Don't see your data source? We're constantly adding support for new databases and file formats.
Contact us and we'll work with you to add support for your specific needs.
Real-World Use Cases
See how organizations use ExisEcho to solve critical data challenges
👥 Master Data Management
Consolidate customer, vendor, and product records from multiple systems into a single source of truth. Eliminate costly duplicate entries in your MDM initiatives.
🚨 Fraud Detection
Identify suspicious patterns in purchasing data, insurance claims, or financial transactions. Catch duplicate submissions and fraudulent actors using slight variations.
💼 Customer Data Quality
Clean your CRM by finding and merging duplicate customer records. Improve marketing effectiveness and customer experience with accurate contact data.
🏢 Vendor Consolidation
Identify duplicate vendor and supplier records across departments. Leverage buying power through consolidated vendor relationships.
📧 Contact List Merging
Combine contact lists from multiple sources while preventing duplicates. Perfect for marketing campaigns, event management, and membership databases.
🔄 Data Migration QA
Validate data quality during system migrations. Ensure source and target systems contain consistent, deduplicated records.
🏥 Healthcare Records
Match patient records across systems to ensure continuity of care. Find duplicate patient entries that could lead to dangerous medical errors.
📚 Research Data
Deduplicate survey responses, research participants, or bibliographic entries. Ensure data integrity for accurate analysis and reporting.
🏠 Address Matching Software
Fuzzy logic address matching for mailing lists, CRM cleanup, logistics, and real estate databases. Handles abbreviations, formatting variations, and city nicknames.
Comprehensive Matching Options
Fine-tune matching behavior for each column in your data
| Option | Description |
|---|---|
| Character Matching | Require exact match of first N characters, or require differences in first N characters |
| Phonetic Match | Match words that sound similar regardless of spelling |
| Equate Synonyms | Treat synonymous terms as equivalent (Bob = Robert, Corp = Corporation) |
| Address Abbreviations | Normalize address variations (St = Street, Ave = Avenue, NYC = New York) |
| Remove Titles | Ignore honorifics like Mr., Mrs., Dr., Prof. |
| Remove Punctuation | Strip punctuation marks before comparing |
| Remove Articles | Ignore articles (a, an, the) in comparisons |
| Remove Custom Values | Define your own list of words to ignore |
| Remove Blanks | Eliminate all whitespace before comparing |
| Remove Consecutive Blanks | Normalize multiple spaces to single spaces |
| Remove Numerics | Ignore numbers in text fields |
| Remove Non-Numerics | Keep only numeric characters for comparison |
| Case Sensitive | Require exact case matching |
| Ignore Word Order | Match regardless of word sequence ("John Smith" = "Smith John") |
| Column Weight | Assign importance weights (0.1 to 10.0) to each column |
From the Blog
Insights on data deduplication, fuzzy matching, and data quality
Fuzzy Logic Excel Add-In vs. Dedicated Deduplication Software
Looking for a fuzzy logic Excel plugin? Learn why purpose-built deduplication software with 15+ matching algorithms delivers dramatically better results than any add-in.
Looking for address matching software?
ExisEcho is purpose-built address matching software that uses fuzzy logic to clean, standardize, and deduplicate messy address data — abbreviations, typos, transposed digits, P.O. boxes, hyphenated numbers, and international formats included. Match across Excel, CSV, SQL Server, and more, with confidence-scored results you can review or auto-merge.
Need to Keep Data On-Premise?
Deploy ExisEcho on your own infrastructure with Docker
For organizations that require data sovereignty, HIPAA compliance, or air-gapped environments — ExisEcho Docker bundles the full fuzzy matching API, admin UI, and Excel Add-in into a single container. Your data never leaves your network.
Ready to Clean Your Data?
Start finding duplicates in minutes with our free trial. No credit card required.